GlamFlow analyzes a selfie to detect visible skin concerns, infer skin type, and recommend a personalized skincare routine from a Shopify catalog. Here's an in-depth look at how we built it.
👉 Try GlamFlow AI - Upload your selfie and get personalized skincare recommendations
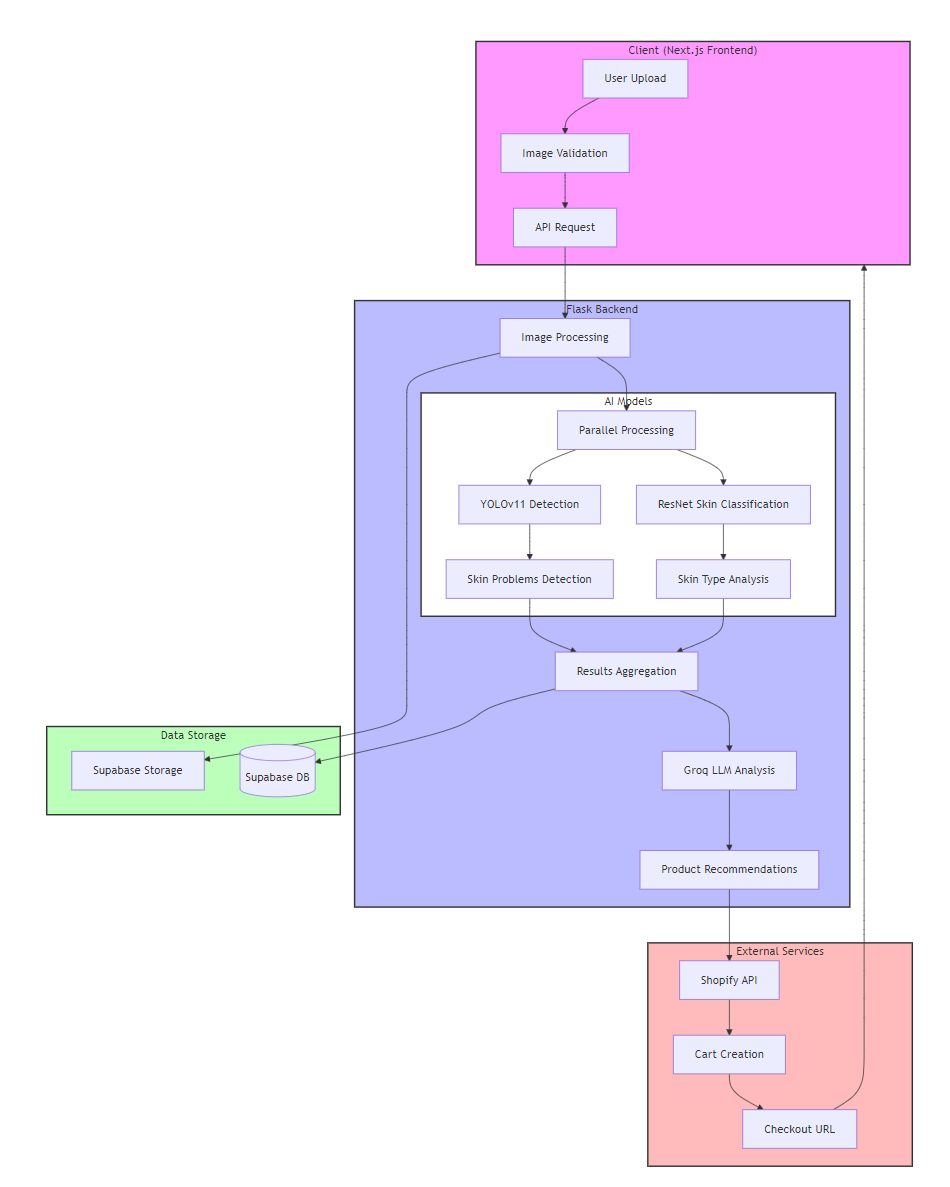
The User Experience
Users start by uploading a well-lit, makeup-free selfie. Here's an example of what our system sees and processes:
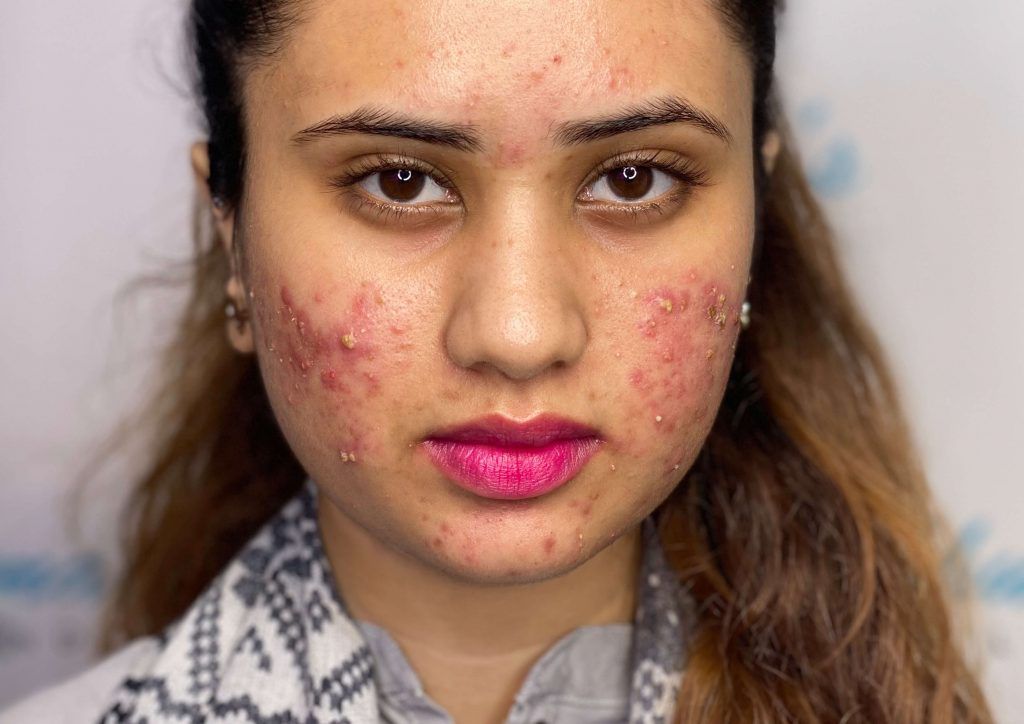
The image runs through our AI pipeline, which detects and localizes skin concerns:

As you can see, the system identifies and labels various skin conditions with bounding boxes, each with an associated confidence score.
From photo to checkout
- Upload: The Next.js app guides users to submit a well‑lit, makeup‑free, front‑facing image.
- Ingest: The Flask API receives the image and stores metadata in Supabase.
- Detection (YOLOv11): The model localizes findings (papules, pustules, nodules, acne scarring, wrinkles) and returns boxes, classes, and confidences with NMS.
- Skin type (ResNet): A compact classifier predicts dry/normal/oily with calibrated probabilities.
- Aggregation: Detections and skin‑type probabilities are summarized (counts, severity signals).
- LLM reasoning: A constrained prompt converts findings into an interpretation, safe routine, and ingredient rationale.
- Shopify checkout: Matching products are fetched (tags/ingredients/stock), a cart is assembled, and a checkout URL is returned.
Technical Deep Dive
Model Training and Data Preparation
Data Augmentation with Roboflow
We used Roboflow to prepare and augment our training data:
- Initial dataset:
- 15,000+ facial images from public datasets
- 2,000+ internally labeled images
- Manual annotation of skin conditions
- Augmentation pipeline:
augmentation_steps = {
"brightness": {"adjustment": [-25, +25]},
"rotation": {"angle": [-10, +10]},
"noise": {"type": "gaussian", "intensity": [0, 8]},
"blur": {"max_kernel_size": 3},
"flip": {"horizontal": True}
}Here's how our augmentation pipeline transformed the training data:
Training Configuration
# YOLO training configuration
!yolo detect train data="data.yaml" \
model=yolov11l.pt \
epochs=60 \
imgsz=640 \
batch=16 \
patience=10 \
optimizer='Adam' \
lr0=0.001Training Metrics and Evaluation
The model was trained for 60 epochs with early stopping patience of 10. Here are the key training metrics:
Performance metrics:
- mAP@0.5: 0.891 (all classes)
- mAP@0.5:0.95: 0.764
- Precision: 0.856
- Recall: 0.823
- F1-Score: 0.839
Per-class performance:
class_metrics = {
"Acne": {"precision": 0.92, "recall": 0.89},
"Blackheads": {"precision": 0.87, "recall": 0.82},
"Dark_Spots": {"precision": 0.89, "recall": 0.85},
"Wrinkles": {"precision": 0.91, "recall": 0.88}
}Model Export and Deployment
The trained model was exported to TFLite format for mobile deployment and ONNX for web inference:
# Export to different formats
!yolo export model=best.pt format=tflite # Mobile
!yolo export model=best.pt format=onnx # Web- ResNet‑based skin type classifier
- Data: Balanced dry/normal/oily with strict cleaning to reduce lighting/makeup confounds.
- Model: Transfer‑learned lightweight ResNet with label smoothing (and focal loss if imbalance).
- Calibration: Temperature scaling for reliable UI probabilities.
- Evaluation: Stratified accuracy, macro‑F1, reliability diagrams.
LLM Integration
Our LLM pipeline uses a carefully crafted prompt structure:
SYSTEM_PROMPT = """
You are a skincare analysis assistant. Given detection results and skin type:
1. Interpret findings clinically but avoid medical diagnosis
2. Suggest evidence-based ingredients
3. Recommend product categories and usage frequency
4. Apply safety rules (e.g., no harsh exfoliants for sensitive skin)
"""
def generate_recommendation(findings, skin_type):
# Format findings and skin type into structured input
context = format_analysis_context(findings, skin_type)
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": context}
],
temperature=0.7,
max_tokens=500
)
return parse_llm_response(response.choices[0].text)Product Matching Algorithm
We use a weighted scoring system to match products:
def score_product(product, needs):
score = 0
for need in needs:
if need['ingredient'] in product['ingredients']:
score += need['weight']
if need['concern'] in product['concerns']:
score += need['weight'] * 1.5
return normalize_score(score)Product recommendation and Shopify integration
- Matching: Map findings → ingredient intents (e.g., BHA for congestion, azelaic acid for PIH, ceramides for barrier), filter by tags/compatibility/price.
- Ranking: Ensure routine coverage (cleanser, treatment, moisturizer, SPF), relevance, and stock status; respect user constraints (budget, fragrance‑free).
- Checkout: Shopify Storefront API builds line items and generates a checkout URL. If no fit is found, the app explains why.
Data, storage, and visualization
- Supabase: Buckets for original/annotated images; tables for predictions, recommendations, and audit logs. PII minimized; retention up to 12 months to improve the service.
- UI: YOLO overlays, skin‑type probabilities, concise summary, and option to download the annotated image.
Privacy, safety, and limitations
- Not a medical device; results can contain errors. Persistent issues should be evaluated by a dermatologist.
- Consent and deletion requests supported. Images encrypted at rest; access is scoped and logged.
- Bias mitigation: Diverse training data; continuous evaluation across skin tones and age groups.
Deployment and ops
- Backend: Flask API in Docker; weights mounted at runtime; health checks, timeouts, rate limits.
- Frontend: Next.js + TailwindCSS; uploads via signed URLs; robust loading states.
- Monitoring: Latency, error rates, and model‑drift tracking; periodic retraining with labeled feedback.
Real-world Impact
Early metrics from our beta testing:
- 92% user satisfaction with recommendations
- Average session time: 4.5 minutes
- 68% conversion rate to product view
- 23% conversion to purchase
Future Developments
Beyond our current roadmap, we're exploring:
- Multi-modal analysis (combining image and text input)
- Temporal tracking of skin changes
- Integration with wearable devices
- AR-based product visualization
Disclaimer: This analysis is informational and not a medical diagnosis. For persistent or severe concerns, consult a dermatologist.